
Data models are the underlying structure of a database. It represents data, including the relationships, semantics and constraints governing it. We need to design the database at the physical, logical, and view levels. There are a couple of different popular approaches such as Inmon (Normalised approach), Kimball (Star Schema), Data Vault and one-big table. DBT uses star schema with sources (where the raw data has been already loaded) that move data to staging models where it’s transformed, cleaned and standardised. The staging models are break down in the in the intermediate models on facts and dimension models to finally create the final models of the tables existing in data storages such as live tables in BigQuery or Snowflake.
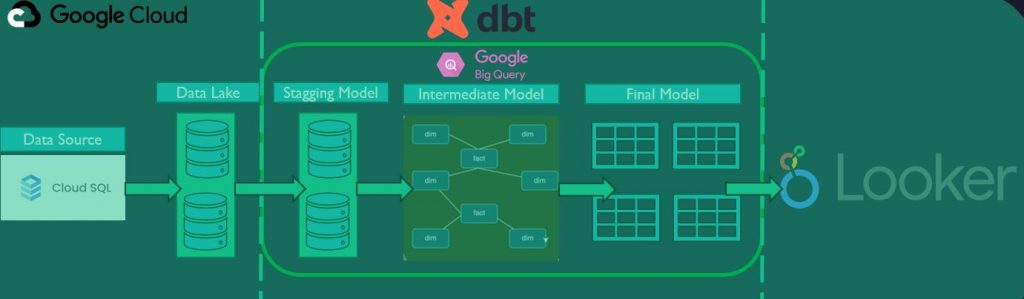
The DBT approach – Star schema
The Kimball model is a star schema. The best resource of information about the approach is the Kimball Group website. The benefits of using this approach are that it’s familiar and well-documented, capable of handling complex scenarios and provides clarity and stability to a data warehouse. To create a star schema:
- Identify facts. Fact tables are the foundation of a data warehouse. They represent an activity that has urgent business priorities. Things that are occurring or already occurred. The fact table grain must be defined on the business definition level; the business definition is what a single record represents, for example, every single click, impression, store visit, etc. Always we want to build it at the lowest possible grain. It’s much easier to aggregate than go the opposite direction. For example, in a shop, many customers may come regularly for a visit and buy different products during a single visit. We can create a fact table for transactions for each product they purchased as we can aggregate by the number of products they bought on a single visit, the number of times customers purchased a particular product and so on. In the fact table, you will have foreign keys to dimensions and aggregate numeric information. We don’t want descriptions or attributes in the fact tables.
- Determine dimensions – Dimensions add context to the fact. It describes things that exist, like people, places or things, e.g. users, companies, products, customers, etc. You can have slowly changing dimensions, for example, office location. The dimension table may include attributes, dates or numeric values (if categorical data). They are usually flat, wide, de-normalised tables. If you use DBT in the staging layer, you would rename the columns, concatenate them there rather than in the dimensions table. Dimension table simply holds breaks down the table with a specific form. One dimension may join multiple fact tables but you want to avoid dimensions joining directly to other dimension tables. The way that it joins is through the keys, foreign keys linking to other tables.
- Develop marts: Marts join facts and dimensions to create custom views. In DBT we call them final models. You can quickly join on the keys to see the total order by the customer, the busiest time of the day and so on.
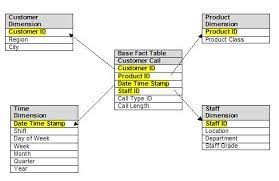
Other approaches
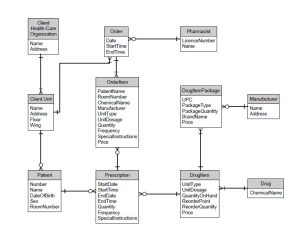
I absolutely loved comparison done by Kahan Data solution in his video. The normalised model is called the Inmon approach because of the name of Bill Inmon, the father of a modern data warehouse. There are no data redundancies, and it requires a lot of joints. The data is stored in a normalised form, and the data is fed into departmental data marts, where the data is filtered down to the specific need. Everything is broken up individually. The advantages are that it only stores thoroughly cleaned data, is easier to model as the sources are normalised data structure, and stores all organisational data. It has disadvantages, such as slower reporting queries as multiple joins are needed and slow startup time as it needs to be cleaned and follows carefully designed business needs before entering the warehouse. Finally, the separate data marts create gaps between departments in a single organisation.
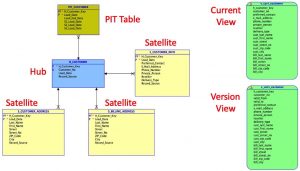
Data Vault. Everything is split into hubs, links and satellites. The hubs and links hold the metadata, and satellites will contain more descriptive values and context. The benefit is that it is simply a representation of your sources without transformation, but it was mainly designed to store many different forms of data. It is intended to be built incrementally; it’s up and running quickly as transformations are applied later. It also helps with the increasing demand for data lineage.
One response to “Data modelling approaches.”
[…] With DBT, you can transform your raw data into valuable insights with confidence, knowing that your models are built and managed with precision and flexibility. To continue reading about data modelling with DBT check our other blog post […]