
Data transformation is a crucial step in any data analytics or business intelligence project. Raw data needs to be moulded into a usable format before it can be analysed, and this is where modelling comes into play. In the world of data analytics, modelling is the process of shaping raw data into its final, transformed state. One tool that has gained popularity in the data modelling arena is DBT (Data Build Tool), which simplifies the modeling process and provides a structured framework for handling data transformations. This article was created based on the training material on DBT Learn
Model in DBT
In DBT, models are the cornerstone of the data transformation process. These models are essentially SQL statements with a .sql file extension. Each model in DBT corresponds to a table or view in your data warehouse. This one-to-one relationship between models and database objects ensures clarity and consistency in your data transformation project.
When it comes to actually materializing these models in the data warehouse, DBT offers a default materialization type: views. Views are a form of virtual tables that display the result of a stored query. This default materialization works well in most cases, but there are situations where you might want to use tables as your materialization choice. Luckily, DBT provides the flexibility to configure your materialization type as a table with a simple line of code, as shown below:
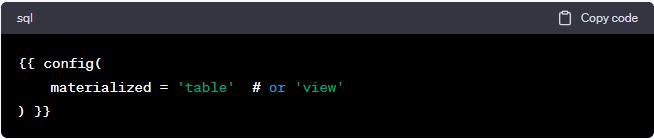
With this configuration, DBT will generate the necessary SQL code to create and manage the specified type of database object during the modelling process.
Materialization Process
When you execute dbt run in the command line, DBT gets to work materializing your models into the data warehouse. For views, this means executing a CREATE OR REPLACE VIEW statement. For tables, DBT generates the necessary DDL (Data Definition Language) or DML (Data Manipulation Language) statements to create and populate the table.
One notable feature of DBT’s materialization process is its intelligence in handling existing database objects. If the model already exists in the data warehouse, DBT will automatically drop the table or view before building the new database object. This feature ensures that your data remains up to date and that no conflicting objects clutter your data warehouse.
“Note: If you are working with BigQuery, you may need to run dbt run --full-refresh for the drop-and-recreate mechanism to take effect.“
Understanding the DDL/DML
DBT provides transparency into the details of the modeling process. You can easily view the exact DDL/DML statements that are executed during the modeling process. This information is accessible through the cloud interface or the target folder in your project directory, allowing you to inspect and verify the SQL code generated by DBT.
Building Dependencies with the ref Function
Building a data transformation project often involves a web of dependencies between various models. In DBT, the ref function plays a pivotal role in creating these relationships. The ref function allows you to build dependencies between models in a flexible way, promoting a modular and shareable code base.
The ref function references the name of the database object created during the most recent execution of dbt run in your specific development environment. This ensures that your code adapts to the current state of the project, maintaining accuracy and consistency. By using the ref function, you not only rely on dependencies but also work seamlessly in diverse development environments.
Moreover, the ref function contributes to the creation of a lineage graph. This graph, managed by DBT, visualizes the dependencies between models, illustrating the order in which they should be built. DBT leverages this lineage information to ensure that your data transformation project is executed with precision.
In conclusion, modeling is a crucial part of data transformation, and DBT simplifies this process through SQL-based models, flexible materialization options, and intelligent handling of dependencies. The ref function, in particular, brings a powerful level of flexibility and precision to your data transformation projects, ensuring that your data is processed accurately and efficiently.
With DBT, you can transform your raw data into valuable insights with confidence, knowing that your models are built and managed with precision and flexibility. To continue reading about data modelling with DBT check our other blog post